crypto🔨 (pbctf 2020)
10 Dec 2020We need to recover the flag from a file that has been encrypted using a random 40000 byte long key using a custom encryption routine, using only the 1 known ciphertext. Overall I found this challenge to be quite interesting and well designed. Only 3 teams solved it over the course of the 48 hour contest (organized by Perfect Blue), and it had a final score of 443 points. This post describes how I solved it during the CTF.
If you simply want to read the solution script, you can find it here. However, if you want to understand how we can get there, let's begin!
Problem Description
We are given two files (encrypt.cc and flag.iso.enc) and the challenge description:
Can you crack a 40000 bit key? 🤨
The encrypted flag is a 1,052,672 byte (~1MB) file, and its file extension likely indicates that it is an encrypted version of an ISO Optical Disc Image file. Clearly, it has been encrypted via encrypt.cc, so let us have a look at its code.
Understanding the Encryption and Planning an Attack
The main function of encrypt.cc simply creates a
CSPRNG object named p with a key size of 40000. It then repeatedly
bitwise XORs the input with a newly produced value from p, and
outputs this result. This means that the code is operating as a
stream cipher. There
are a collection of
attacks that
apply generally over most stream ciphers, but certain special
conditions might need to apply for their use. For example, a XOR-based
stream cipher (such as what we have here) is susceptible to
bit-flipping attacks; however we are working as a purely passive
adversary with only 1 known ciphertext, so the number of possible
attacks are dramatically fewer. In particular, the only real attack we
have is that the PRNG (pseudo random number generator) is somehow
"broken" and the key stream produced from it can be recovered.
Thus we must dive into the implementation of the CSPRNG class, which
is templated on N, the size of its key and its internal state in
bytes. The state maintained by the CSPRNG is:
char m_key[N];
char m_state[N];
int m_ofs;
As part of its initialization, it sets m_ofs to 0, and assigns
m_key and m_state via getrandom from sys/random.h, which means
the initial state is (for our purposes) fully random. This means that
the attack must lie in how the PRNG produces its random numbers. This
is in the method called next():
char next()
{
char o = 0;
for (int i = 0; i < N; i++) {
o ^= m_state[(m_ofs+i)%N]&m_key[(i)%N];
}
m_state[m_ofs++] = o;
m_ofs = (m_ofs+1)%N;
return o;
}
The first thing that stands out is that m_ofs is incremented twice
(both as a post-increment when setting m_state[m_ofs++], and as an
explicit addition-and-set in the next line). Since N is odd, this
means that only half the number of bytes of m_state are changing as
next() is called over time, and the other half remain unchanged
throughout the code. This is not yet enough for us to attack the
system, however.
The next thing to notice is that the m_key is never changed (thus we
can treat it as an unknown but completely constant value for our
purposes, since we are only analyzing a single ciphertext), and that
it is only m_state that changes. Thus the total maximum internal
state of the RNG is ~20,002 bytes (20,000 bytes for m_state and ~15
bits for the m_ofs to store even numbers between 0 and 40,000). This
is fairly large. If this was (much) smaller, we may have ended up with
a PRNG with a small fixed period which we could then have applied
statistical techniques on the ciphertext to recover the
plaintext. Unfortunately, this attack is not applicable in this
challenge.
And so, we look into how the state is actually being stored and how
the random data is being computed. We notice that all the operations
that are being performed on o and m_state are bitwise operations
(i.e., bitwise AND & and bitwise XOR ^). Without any shifts,
rotates, additions, multiplications, etc., there is no way for
different bits of each byte to interact amongst each other, and each
bit position can be treated completely independently. Thus, we can
reimagine this PRNG (that produces bytes) as 8 separate (independent)
PRNGs (that produce bits). Each of them have their own initial
starting state (of m_state and m_key) that is independent from one
another, and consists of 40,000 + 40,000 bits of information, with a
state size of ~20,000 bits each.
Recognizing the PRNG
At this point, we know that we have to defeat a PRNG that produced
bits and must start to sketch out what the PRNG is actually doing. For
this, we take a smaller sized state (say 10 bits) and sketch out what
each next() operation would look like. We find that the key strictly
acts like a selection (since it is an & with either a 0 or a 1)
of bits of the state that are XOR'd with each other, and then placed
into one of the bits, and then the offset is moved over, and the
process repeats.
Instead, if we think of the offset not changing, we can model it by
rotating m_state towards the left by 2 (because of the double
increment that we noticed earlier) upon each call of next().
Visualized this way, this looks suspiciously like a Linear-Feedback Shift Register (or LFSR for short). It is not exactly an LFSR because an LFSR would shift by 1 each time, but it is close enough that we can probably use similar attacks as can be used on an LFSR. Let's name this PRNG a "doubly-shifted-LFSR" (this is my own name for it, since I am not aware of a commonly known name for it; if you are aware of one, please do let me know!).
Attacking the Doubly-Shifted LFSR
At this point, I was curious as to whether we could show a perfect equivalence between this doubly-shifted-LFSR and a normal LFSR. If we could show this equivalence, then we would be able to directly use LFSR attacks on it, without needing to adapt them at all. My hypothesis for this came from the fact that if we had the key at all odd places in the doubly-shifted LFSR as either all 0s or all 1s, then we would immediately have an LFSR of half the size as the doubly-shifted LFSR (in the 0 case, those parts of the state are completely ignored; and in the 1 case, it leads to a constant that gets XOR'd with the state at each point, which can be modeled by an LFSR).
To convince ourselves that this is indeed the case, we can implement the doubly-shifted LFSR in Python, and also implement a standard LFSR recovery program (described soon), and use this to try to recover the minimal LFSR from the doubly-shifted LFSR's output. As it turns out, it is indeed possible to recover an N-bit LFSR for any N-bit doubly-shifted LFSR (at least as far as a few dozen tests with random initial states and varying values of N showed). At times, it may even recover a smaller LFSR, which can happen when (say) there was some sort of pattern to the key & state in the odd-indexed positions (like the all 0s or all 1s pattern mentioned above). While we haven't yet proven that this is the case, it is a safe enough assumption to make that a doubly-shifted LFSRs are equivalent to standard LFSRs, and we can proceed with attacking it as if it is simply a standard LFSR. If (for any reason) this assumption ends up failing, we will simply have to look for a new way to attack it. Thankfully the assumption holds at least in our case.
To recover the minimal LFSR for a specific output bitstream, one can
use the Berlekamp-Massey
algorithm. This
algorithm provides the minimal linear recurrence that generates the
exact same output bitstream as was given as input to the algorithm. To
be able to recover an N bit LFSR, we require (at least) 2*N bits
of output. Thus, if we are able to obtain 2*N bits of the key
stream, we can recover the fully structure of the LFSR in the
challenge. Since LFSRs are invertible, we can move forwards and
backwards in the LFSR to obtain any other portion of the keystream we
want/need once we have recovered its internal structure. Due to this
forward and backward nature, any 2*N continuous bits are
sufficient to obtain its structure and to recover the entire
keystream.
However, all we have is an encrypted (i.e. XOR'd) stream. How can we recover the keystream to perform the attack?
Attacking the ISO File Format
The ISO Optical Disc Image file format is standardized as the ISO 9660 technical standard which describes the file system used for optical media. Since our flag.iso.enc is an encrypted version of this format, we can look for peculiar properties that might help us obtain any information we need. For a XOR-based cipher, if we have a portion of the plaintext known, then we immediately know that portion of the keystream. Thus, we are looking for regions of the ISO file that have fixed known values (such as magic numbers, or file/segment/structure sizes etc.) or are amongst a small number of possible values (for example, if a field is a boolean, or is from a small collection of integers).
If we can find a contiguous segment of 80,000 bytes, then we immediately have a full break on the system. Reading through the Wikipedia page on ISO 9660, we find this:
The system area, the first 32,768 data bytes of the disc (16 sectors of 2,048 bytes each), is unused by ISO 9660 and therefore available for other uses.
This is interesting. Unused areas are usually set of 0s (i.e. NUL bytes) by many programs/utilities, and thus it is possible that the first 32,768 bytes of the file are directly the keystream. Indeed if we check a few random ISO files downloaded from the internet (such as from Linux distros) those first few bytes are always 0s. Unfortunately, this is less than the 80,000 bytes we need, but it is a good start. It also indicates to us that there may be more contiguous regions around.
Reading further, we can find some other regions of the disc that are
fixed values, or are amongst a small set of values, but are not long
enough for us to perform the attack easily. At this point, we can
simply stare at the actual bytes in the few downloaded ISO files to
see if there are any large contiguous regions that existed on all of
them. And yes, indeed there are! The last few 10s of thousands of
bytes of the file seem to always be 0s. At this point, we can make the
assumption that 2*N bytes might be 0s in the plaintext version of
flag.iso.enc too, and thus implement the attack. If our assumption
is wrong, the recovered key material will clearly be wrong (since we
won't obtain the required ISO 9660 headers at the start of the file)
and if so, we can look for other regions to attack. Thankfully this
assumption works out in the end!
Putting it all together
Now that we have a nice overall plan of attack, it is time for us to
write down the attack script. We perform the attack on each bit
position separately, by iterating over all 8 possible
bit_positions. We begin by using the Berlekamp-Massey
Algorithm
on the last BACKWARD_DEPTH bits extracted from
flag.iso.enc. We use a BACKWARD_DEPTH that is
larger than 2*N so that we can perform extra sanity checks. When we
perform the Berlekamp-Massey Algorithm, we obtain the minimal LFSR
that could represent the bits we gave it, which means that if this
LFSR is larger than 40,000 (our value of N) then we know for a fact
that at least one value in the plaintext in the last BACKWARD_DEPTH
bytes of the file is non-zero. Thankfully, this is not the case, and
we are able to obtain a set of 8 LFSRs of size 40,000, one for each
bit.
Since this algorithm is time consuming, we run the code using PyPy which is an alternate implementation of Python which is significantly faster since it uses a JIT compiler. Nonetheless, this still takes a few minutes to run, and thus it is a good idea to cache the results when iterating on the attack.
Once we have recovered these 8 LFSRs, we need to run them in reverse to obtain the keystream for the rest of the file. Since the LFSR needs to look at ~40,000 values of its state for each bit it can produce, as you would expect, this is also slow. It is however helped by PyPy again.
Once we have obtained the whole keystream for each bit, we can merge
these keystreams to get it as a byte-based keystream, and use this to
recover the plaintext by simply performing a bitwise XOR across the
ciphertext. We output this to a file output.iso.
If we run the final script we get this:
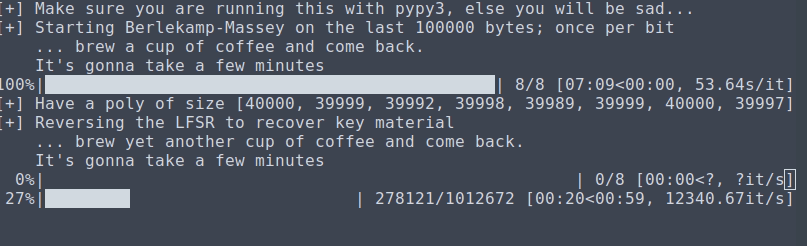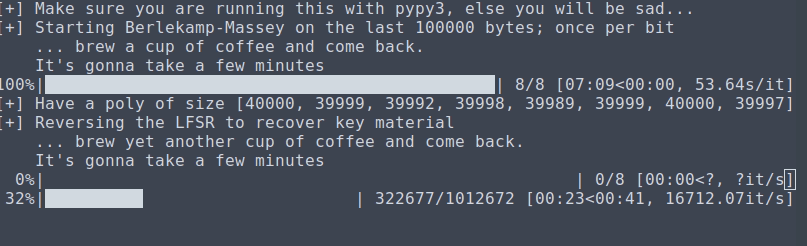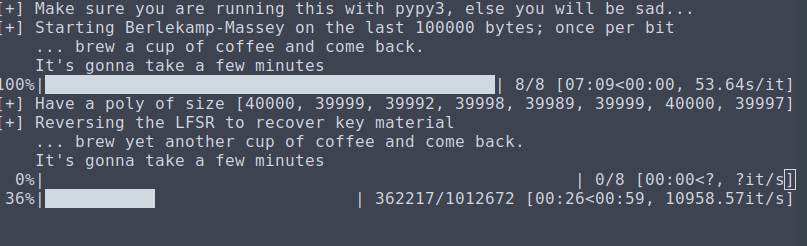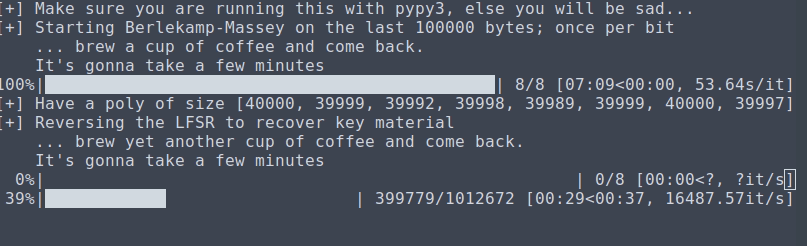
$ pypy3 ./solve.py
[+] Make sure you are running this with pypy3, else you will be sad...
[+] Starting Berlekamp-Massey on the last 100000 bytes; once per bit
... brew a cup of coffee and come back.
It's gonna take a few minutes
100%|███████████████████████████████████| 8/8 [07:09<00:00, 53.64s/it]
[+] Have a poly of size [40000, 39999, 39992, 39998, 39989, 39999, 40000, 39997]
[+] Reversing the LFSR to recover key material
... brew yet another cup of coffee and come back.
It's gonna take a few minutes
100%|███████████████████████████████████| 8/8 [07:13<00:00, 54.16s/it]
100%|████████████████████| 1012672/1012672 [00:54<00:00, 18431.75it/s]
[+] Reversed key material.
[+] Merged bits.
[+] Recovered plaintext.
[+] Saved to output.iso!
Approximately 10~15 minutes of execution later, we obtain output.iso
which we check to see that it is indeed an ISO file:
$ file output.iso
output.iso: ISO 9660 CD-ROM filesystem data 'CDROM'
We then mount the file mkdir temp && sudo mount output.iso temp && cd
temp, and inside the file-system, we find a single file -
flag.htm which is a rendered version of the flag:
pbctf{y0u_c4n_s0lVE_To3plitZ_SYStems_1n_SQuAre_TiMe}
Closing Thoughts
Overall, this challenge was super fun to solve. It was a nice mix of understanding file formats, making simple assumptions to make progress, and validating those assumptions as we go along.
For what it's worth, the flag that we obtain refers to the Toeplitz
matrix which is a
matrix A where A[i][j] == A[i+1][j+1] for all i and j. I was
not aware of what this matrix is called, but indeed this can be used
to nicely model what the PRNG in this problem is doing. And indeed
there appears to be a quadratic time algorithm (rather than the naive
cubic time algorithm for normal matrices) to solve an equation of the
form Ax = b where A is a Toeplitz matrix. This algorithm can thus
be used to solve this challenge, and this appears to be the expected
solution (at least based upon what's written in the flag). This is
definitely more elegant, and indeed along my path towards solving it,
I did write it down in this matrix form, and I guessed that there must
be a faster solution than cubic to be able to solve this equation due
to the fewer degrees of freedom, but I didn't know what this matrix
was called, and thus was unable to search for the right things to find
it. However, I was able to recognize parallels to the LFSR (which is a
classic, albeit broken, way to implement a PRNG), which ended up being
sufficient to solve the challenge.
Cheers to braindead of Perfect Blue for making this challenge. This was a lot of fun :)
