Mixed (Google CTF 2022)
05 Aug 2022A byte-compiled Python file, with a patch to the cpython source showing that the opcodes have been scrambled. Let's go!
Mixed was a really fun challenge from the recent Google CTF, that zaratec and I worked on together, each focusing on a different aspect. You can find her write-up here, which covers a lot more about the pattern recognition side of things that I skim over.
Problem Description
We are given two files (x.pyc and patch) and the challenge description:
A company I interview for gave me a test to solve. I'd decompile it and get the answer that way, but they seem to use some custom Python version... At least I know it's based on commit 64113a4ba801126028505c50a7383f3e9df29573.
Early Analysis
Since we are told that it is a custom Python version and that existing decompilers wouldn't work, it is not worth spending time early on to get a decompiler working. Instead, we jumped right into understanding the patch. As a tiny precursor to that, mostly to save some time since it involves compiling Python from scratch, we set up a local environment while still looking at the patch.
The CPython source repository at the relevant
commit
shows that it is a fairly recently commit, Python 3.11 alpha 7. Also,
since we have to deal with a byte-compiled Python .pyc file, which
is often version dependent, it's best we get a nearby version (or
preferably the exact commit). Since it is faster to pull a nearby
version, I did that (using pyenv:
pyenv install 3.11.0b3 and pyenv local 3.11.0b3), and then kicked
off a compilation of the specific commit, after applying the
patch. Our aim here is to get some reasonable environment set up
quickly, and refine it as time goes, if necessary.
Looking at the patch itself, it patches just two files,
Lib/opcode.py, and a tiny change to Python/ceval.c, to disable an
optimization called "computed gotos". We can largely ignore this
change to ceval.c since it is not a functionality change (to keep
the optimization enabled, the challenge author would've needed to
patch more files, so our guess is that it was easier to just disable
the optimization; we do not believe this changes the challenge's
difficulty though, other than reducing the size of the overall patch).
Looking at the patch to opcode.py itself, we see that it replaces
out the pre-defined opcode numbers for various opcodes with a random
permutation. This permutation is split into two parts: perm permutes
the first 90 possible opcode values, while perm2 permutes amongst
the next 110. This split reduces the space of permutations possible,
simplifying the challenge, but (at least at the moment) not by
much. In particular, we are still not in brute-force-able
range. However, this separation of upto 90 vs. above 90 comes in handy
later on, to help provide sanity checks throughout the code.
Why 90 in particular though? Looking at the source is helpful here:
HAVE_ARGUMENT = 90 # Opcodes from here have an argument:
The last bit of the patch stores the permuted opcodes away to
/tmp/opcode_map but since we don't have that, we can ignore it.
Another good thing to check for before going much further: use the
command strings which can find printable strings within a binary
file. A few selected interesting lines from running strings x.pyc
are listed below:
random
seedZ
randint
E/usr/local/google/home/xxxxxxxxx/yyyy/zzzzzzzzzzzzzzzz/xxxxxxxxxxx.py
Thanks for playing!r
game1.<locals>.w
Fuel:r
wasdz
Crash!r
Nice!)
game1r1
Math quiz time!)
difference
productr
ratio
remainder from division
What is the %s of %d and %d?r2
game2rD
Speed typing game.z
Text: Because of its performance advantage, today many language implementations
%0.2f seconds left.
time
game3rO
Nz!Pass 3 tests to prove your worth!z
seed:
:zGYou can drive to work, know some maths and can type fast. You're hired!z
Your sign-on bonus:s2
decoder
mainrR
<module>rS
From just these few lines, we can gather that there are 3 games
("drive to work", "know some maths", and "type fast"), that they're
likely defined as functions game1, game2, and game3
respectively, and that there is a function main that runs those 3,
and potentially runs a "decoder". We also see indications that there
might be the use of the Python standard library
random.seed,
which indicates that the built in pseudo random number generator
(PRNG) is used, but that it likely has the same output each time
(since we don't see a os.urandom or time.time or similar nearby).
Divide and Conquer
We now had an approximate idea of what the challenge involved, and what we might need to do to figure it out. Specifically, as soon as we were able to recover what opcode number each operation was mapped to, we would be able to run the binary (modulo a tiny patch to CPython, replacing the random permutation in the patch with instead a hard-coded set of values). We weren't sure however, if being able to run the binary would be sufficient, so we would likely need a decompiler, or at the very least, a disassembler. Thus, there were two main tasks: identify opcodes, and implement a disassembler.
Thus, zaratec and I took up those tasks respectively. Her task of
identifying opcodes through witchcraft pattern recognition and
smart guessing is probably best understood by this wonderful sentence
she wrote: "you just gotta feel the bytecode". I personally focused on
tooling, specifically to try to make her task easier, and hopefully be
able to decompile this x.pyc. This allowed each of us to focus on
complementary tasks but still allowed us to work largely
independently.
It is also interesting to note here, that we don't need a full-blown
decompiler, we just needed to decompile x.pyc. This allows for a
simpler approach of generating a particular x.py such that it
compiles approximately to x.pyc (using, say, python3 -m
compileall x.py). Thus, a large part of pattern recognition involved
compiling progressively improved test files, and checking against the
output.
The Unfortunate dis
Python has an built-in disassembler called
dis. Given a code
object, it will disassemble it to produce, for lack of a better term,
Pythonic-assembly. Unfortunately, we do not have known values for the
opcodes, so it is almost guaranteed to produce garbage early
on. However, our aim is to improve upon dis, by using the guesses
for opcode values we provide, to produce x.pyc disassembly of
high-enough quality that we can then match it against the
compiled-and-disassembled version of our test Python file.
It seemed like dis would be an ideal starting point to write a
disassembler that worked and got us past the finish line. Yet it
turned out to be more annoying than I had initially guessed for a
variety of reason, so eventually I decided to abandon this approach,
and write my own custom disassembler from scratch. But I'm getting
ahead of myself, let's talk more about the dis-based disassembler.
Sidenote: by default, the dis link you get from a search engine
points at 3.10, as of writing (since 3.11 has not yet released). We
need 3.11 though, which we can get to by clicking on the version
number in the top left; the link here jumps directly to 3.11. We did
not realize this early enough, but there are significant changes
between 3.10 and 3.11, and noticing this earlier would've helped speed
up some of our work. We weren't slowed too much by the differences
though, thankfully, and we figured out the differences just when they
started to matter.
Initial Wins
While I was still working on getting dis running, zaratec seemed to
have already started recognizing some patterns by staring at a
hexdump, and sent over the following:
guesses:
*96 (0x60):LOAD_CONST
*171 (0xAB):IMPORT_NAME
*150 (0x96):STORE_NAME
this is the pattern for imports at the beginning of the file
Recognizing that looking at the opcodes in the output would be
crucial, and also that we'd likely want to be able to quickly test
changes, I wrote up a patch to dis.py and (the aforementioned)
opcode.py:
diff --git a/Lib/dis.py b/Lib/dis.py
index 205e9d8d19..aabaf37183 100644
--- a/Lib/dis.py
+++ b/Lib/dis.py
@@ -310,6 +310,8 @@ def _disassemble(self, lineno_width=3, mark_as_current=False, offset_width=4):
fields.append(' ')
# Column: Instruction offset from start of code sequence
fields.append(repr(self.offset).rjust(offset_width))
+ # Column: Opcode number
+ fields.append(str(self.opcode).rjust(5))
# Column: Opcode name
fields.append(self.opname.ljust(_OPNAME_WIDTH))
# Column: Opcode argument
diff --git a/Lib/opcode.py b/Lib/opcode.py
index 40b6fdd2e0..01ab16a5b7 100644
--- a/Lib/opcode.py
+++ b/Lib/opcode.py
@@ -61,10 +61,23 @@ def jabs_op(name, op, entries=0):
perm2 = list(range(200-90))
import sys
-if "generate_opcode_h" in sys.argv[0]:
- random = __import__("random")
- random.shuffle(perm)
- random.shuffle(perm2)
+import os
+if os.getenv("RANDOMIZE"):
+ print("randomizing now")
+ random = __import__("random")
+ random.shuffle(perm)
+ random.shuffle(perm2)
+elif os.getenv("FROMFILE"):
+ print("reading from file")
+ with open('./opcode_map') as f:
+ data = [int(x.split(' ')[0]) for x in f.read().strip().split('\n')]
+ perm = data[:len(perm)]
+ perm2 = [x - 90 for x in data[len(perm):][:len(perm2)]]
+ assert len(perm) == len(range(90))
+ assert len(perm2) == len(range(200 - 90))
+ del data
+else:
+ print("not randomizing")
def_op('CACHE', perm[0])
def_op('POP_TOP', perm[1])
This patch would allow us to use a hand-written ./opcode_map file
(literally a map from numbers to opcode names) by invoking
FROM_FILE=1 ./cpython/python.exe ./disassembly.py ./x.pyc, using
disassembly.py:
import sys
import dis
import marshal
with open(sys.argv[1], 'rb') as f:
f.seek(16)
m = marshal.load(f)
print(m.co_code)
dis.dis(m)
This already started giving us a more readable (albeit incorrect) view on the data we were seeing.
Soon after, zaratec recognized that x.pyc would load 3 modules,
create 7 functions.
We were making nice progress!
Managing Guesses
As I got new guesses, I would manually edit the ./opcode_map file I
mentioned earlier, but this was inefficient, so I whipped up a small
tool, set.py:
import sys
import time
with open('./opcode_map.bak') as f:
data = [x.split(' ') for x in f.read().strip().split('\n')]
known = {
97: 'RESUME',
96: 'LOAD_CONST',
171: 'IMPORT_NAME',
151: 'STORE_NAME',
99: 'MAKE_FUNCTION',
49: 'RETURN_VALUE',
}
for opnum, opcode in known.items():
print(opnum, opcode)
idx_name = [i for i, (x, y) in enumerate(data) if y == opcode][0]
idx_op = [i for i, (x, y) in enumerate(data) if int(x) == opnum][0]
data[idx_name][0], data[idx_op][0] = data[idx_op][0], data[idx_name][0]
with open(f'./opcode_map', 'w') as f:
f.write('\n'.join(' '.join(x) for x in data))
This tool would allow us to add stuff to the known set, allowing for
quick testing without needing to manually mess around with the
semi-fragile opcode_map file. By this point, I've already added a
few more guesses we'd got.
However, soon it became hard to keep track of the quality of the
guesses. Specifically, which guesses were high-quality "we practically
can guarantee this is valid" and which ones were "idk, try this and
see if it helps". Thus, I decided to patch dis.py yet again:
diff --git a/Lib/dis.py b/Lib/dis.py
index 205e9d8d19..f3284edf92 100644
--- a/Lib/dis.py
+++ b/Lib/dis.py
@@ -290,6 +290,16 @@ def _disassemble(self, lineno_width=3, mark_as_current=False, offset_width=4):
*mark_as_current* inserts a '-->' marker arrow as part of the line
*offset_width* sets the width of the instruction offset field
"""
+ with open('semitrusted', 'r') as f:
+ semitrusted = f.read().split('\n')
+ with open('trusted', 'r') as f:
+ trusted = f.read().split('\n')
+ if self.opname in trusted:
+ guess = ''
+ elif self.opname in semitrusted:
+ guess = '?'
+ else:
+ guess = '??'
fields = []
# Column: Source code line number
if lineno_width:
@@ -310,8 +320,10 @@ def _disassemble(self, lineno_width=3, mark_as_current=False, offset_width=4):
fields.append(' ')
# Column: Instruction offset from start of code sequence
fields.append(repr(self.offset).rjust(offset_width))
+ # Column: Opcode number
+ fields.append(str(self.opcode).rjust(5))
# Column: Opcode name
- fields.append(self.opname.ljust(_OPNAME_WIDTH))
+ fields.append((guess + self.opname).ljust(_OPNAME_WIDTH))
# Column: Opcode argument
if self.arg is not None:
fields.append(repr(self.arg).rjust(_OPARG_WIDTH))
@@ -381,7 +393,11 @@ def _get_name_info(name_index, get_name, **extrainfo):
and an empty string for its repr.
"""
if get_name is not None:
- argval = get_name(name_index, **extrainfo)
+ try: # TEMP TEMP TEMP
+ argval = get_name(name_index, **extrainfo)
+ except IndexError: # TEMP TEMP TEMP
+ print(f"IndexError for get_name({name_index=}, {get_name=}, {extrainfo=})")
+ return UNKNOWN, ''
return argval, argval
else:
return UNKNOWN, ''
This allowed us to keep track of files named trusted and
semitrusted that we could dump opcodes into. Additionally, with all
the guesses that we had, we had started getting weird flakiness in the
disassembler, thus I added some "error handling" too (that would
convert to a soft error but continue going).
As a snapshot of what we were guessing at the time, set.py:
import sys
import time
def assert_same_boundary(x, y):
x = int(x)
y = int(y)
assert (x < 90) == (y < 90), f'{x=} {y=}'
with open('./opcode_map.bak') as f:
data = [x.split(' ') for x in f.read().strip().split('\n')]
known = {
# Mostly figured out
97: 'RESUME',
96: 'LOAD_CONST',
171: 'IMPORT_NAME',
151: 'STORE_NAME',
99: 'MAKE_FUNCTION',
49: 'RETURN_VALUE',
# Random guesses
# 98: 'LOAD_GLOBAL',
32: 'CACHE',
# 50: 'LOAD_GLOBAL_BUILTIN',
142: 'PRECALL',
107: 'CALL',
# Change away random shit
48: 'GET_AITER',
99: 'DELETE_GLOBAL',
}
semitrusted = set([
# 'LOAD_GLOBAL',
'LOAD_GLOBAL_BUILTIN',
'CACHE',
'PRECALL',
'CALL',
])
untrusted = set([
'GET_AITER',
'DELETE_GLOBAL',
])
with open('trusted', 'w') as f:
f.write('\n'.join(list(set(known.values())-semitrusted-untrusted)))
with open('semitrusted', 'w') as f:
f.write('\n'.join(list(semitrusted)))
for opnum, opcode in known.items():
print(opnum, opcode)
idx_name = [i for i, (x, y) in enumerate(data) if y == opcode][0]
idx_op = [i for i, (x, y) in enumerate(data) if int(x) == opnum][0]
assert_same_boundary(data[idx_op][0], data[idx_name][0])
data[idx_name][0], data[idx_op][0] = data[idx_op][0], data[idx_name][0]
with open(f'./opcode_map', 'w') as f:
f.write('\n'.join(' '.join(x) for x in data))
Something is Odd
zaratec had mentioned a couple of times that some bytes within the disassembly and the hexdump had not matched (indeed, we often saw extraneous bytes). This had began quite a while before the snapshot above. I had initially chalked these oddities up to "something going weird with the disassembler since we are changing opcodes while a disassembler running using those opcodes is being modified". I thought this would fix itself as we discovered more opcodes. However, it had started to become quite painful to keep track of this, thus I decided to root-cause where those bytes were coming from.
Interestingly, those bytes were not coming from dis behaving
weirdly, or even dis reading from opcodes.py. Instead, the input
that dis was receiving itself was incorrect, and was a
lie. Following through further, it appeared that marshal, a C module
that serializes/parses the bytes from/into Python objects was giving
us bad bytes. Furthermore, this seemed to be impacted by the
opcodes.py file itself.
I was in no mood to modify C code to get the marshal to work better,
nor was I sure what other interactions might happen in doing so, since
it was a cross-language interaction that was behaving weirdly. It was
quite late at night too, and as one knows, late night is the worst
time to write C, apart from all the other ones.
Thus, I decided it was time to write my own custom disassembler from scratch!
New Beginnings
This new disassembler, known manual_disassemble.py even though I
should've named it custom_disassembler.py or something (oh, the
perils of naming something when sleepy), was designed to learn from
the experiences of working with dis. However, it didn't need to be
as generic as dis itself. Instead, it could be as x.pyc-specific
as we wanted.
Thus, I asked zaratec to provide me with a list of offsets of where
the functions are (I couldn't trust marshal, not even an unmodified
Python3 instance of marshal, just in case some opcode permutation
would mess with it). Through some pattern recognition, she gave me
such a list, which I hard-coded into the custom disassembler. I later,
at one point, noticed a stray code object w, which was interesting
to discover to be a function defined within a function.
With this, we now had the beginnings of a custom disassembler
manual_disassembly.py:
from pwn import *
context.endian = 'little'
with open('./x.pyc', 'rb') as f:
pyc = f.read()
func_starts = {
'Global': 0x2a,
'ks': 0x94,
'cry': 0x20e,
'fail': 0x370,
'game1': 0x489,
'w': 0x7a2, # tentatively defined inside game1
'game2': 0xc0c,
'game3': 0x105f,
'main': 0x1654,
}
known_ops = {
# opnum: (name, hasArg)
96: ('LOAD_CONST', True),
171: ('IMPORT_NAME', True),
150: ('STORE_NAME', True),
99: ('MAKE_FUNCTION', True),
49: ('RETURN_VALUE', True),
97: ('RESUME', False),
185: ('LOAD_GLOBAL', True),
188: ('LOAD_ATTR', True),
191: ('PRECALL', True),
142: ('CALL', True),
1: ('POP_TOP', True),
}
global_vals = {
0: 'print',
2: 'sys',
}
for funcname, funcstart in func_starts.items():
print(f'{funcname}:')
codelen = u32(pyc[funcstart - 4:][:4])
code = pyc[funcstart:][:codelen]
nops = 0
idx = 0
while idx < len(code):
op = u8(code[idx:][:1])
arg = u8(code[idx+1:][:1])
if op == 32 and arg == 0:
nops += 1
idx += 2
continue
elif nops > 0:
print(f' ...{nops} nops...')
nops = 0
if op in known_ops:
opname, hasargs = known_ops[op]
if opname == 'CALL':
print(f' {op}\t{opname} with {arg} arguments')
elif opname == 'PRECALL':
print(f' {op}\t{opname} with {arg} arguments')
elif opname == 'LOAD_GLOBAL':
if arg in global_vals:
print(f' {op}\t{opname} {arg} ({global_vals[arg]})')
else:
print(f' {op}\t{opname} {arg} (?????)')
elif hasargs:
print(f' {op}\t{opname} {arg}')
else:
if arg == 0:
print(f' {op}\t{opname}')
else:
print(f' WEIRD: {opname} unexpected arg {arg} ({funcname} : {hex(funcstart+idx)})')
else:
print(f' {op}\t<{op}>')
idx += 2
print()
This allowed us to more easily and quickly improve on the quality of output, and as we discovered more about the opcodes, the output would incrementally improve.
I should note that Python's byte-code uses a stack-based architecture, and thus we do not need to worry about registers and such. It would help to keep better track of the stack itself, if say one were building a decompiler, but due to our "recompile to same" style of manual decompilation, I decided not to bother with keeping track of stack effects.
It had gotten even further late into the night though, and we were tired, so we wrote a message on our Discord that we would finish this challenge when awake again.
Coffee Gives You Energy
Once awake and fully caffeinated, we could begin work on improving this more!
zaratec discovered binary operations, and this started improving the output quite a bit.
I also decided to start trusting marshal and dis a tiny
bit. Specifically, since the opcode permutation only affects opcodes,
it would be fine to reuse non-opcode aspects. Additionally, I was only
using them to provide debug output, and not impact the actual
disassembly. This way, these modules stays untrusted for the most
part, and cannot affect things too negatively.
I also improved the readability of the output a little. Quality of life improvements are often worth it in how much they speed up noticing patterns.
diff --git a/manual_disassemble.py b/manual_disassemble.py
index f8cf184..1574964 100644
--- a/manual_disassemble.py
+++ b/manual_disassemble.py
@@ -1,17 +1,29 @@
from pwn import *
+import marshal
+import dis
context.endian = 'little'
with open('./x.pyc', 'rb') as f:
pyc = f.read()
+mod = marshal.loads(pyc[16:])
+code = type(mod)
+funcs = {
+ x.co_name: x
+ for x in mod.co_consts
+ if isinstance(x, code)
+}
+funcs[mod.co_name] = mod
+funcs['w'] = funcs['game1'].co_consts[1]
+
func_starts = {
- 'Global': 0x2a,
+ '<module>': 0x2a,
'ks': 0x94,
'cry': 0x20e,
'fail': 0x370,
'game1': 0x489,
- 'w': 0x7a2, # tentatively defined inside game1
+ 'w': 0x7a2,
'game2': 0xc0c,
'game3': 0x105f,
'main': 0x1654,
@@ -30,48 +42,97 @@ known_ops = {
191: ('PRECALL', True),
142: ('CALL', True),
1: ('POP_TOP', True),
+ 198: ('BINARY_OP', True),
+ 98: ('LOAD_FAST', True),
+ 0x8d: ('STORE_FAST', True),
}
-global_vals = {
- 0: 'print',
- 2: 'sys',
+guess_ops = {
+ # TODO TODO
+}
+
+binary_ops = {
+ 0: 'ADD',
+ 1: 'AND',
+ 2: 'FLOOR_DIVIDE',
+ 3: 'LSHIFT',
+ 4: 'MATRIX_MULTIPLY',
+ 5: 'MULTIPLY',
+ 6: 'REMAINDER',
+ 7: 'OR',
+ 8: 'POWER',
+ 9: 'RSHIFT',
+ 10: 'SUBSTRACT',
+ 11: 'TRUE_DIVIDE',
+ 12: 'XOR',
+ 13: 'INPLACE_ADD',
+ 14: 'INPLACE_AND',
+ 15: 'INPLACE_FLOOR_DIVIDE',
+ 16: 'INPLACE_LSHIFT',
+ 17: 'INPLACE_MATRIX_MULTIPLY',
+ 18: 'INPLACE_MULTIPLY',
+ 19: 'INPLACE_REMAINDER',
+ 20: 'INPLACE_OR',
+ 21: 'INPLACE_POWER',
+ 22: 'INPLACE_RSHIFT',
+ 23: 'INPLACE_SUBTRACT',
+ 24: 'INPLACE_TRUE_DIVIDE',
+ 25: 'INPLACE_XOR'
}
for funcname, funcstart in func_starts.items():
- print(f'{funcname}:')
+ f = funcs[funcname]
+ print(f'{funcname}({",".join(f.co_varnames[:f.co_argcount])}):')
+ print('\n'.join('\t' + x for x in dis._format_code_info(f).split('\n')))
+ line_starts = {line:offset for line,offset in dis.findlinestarts(f)}
codelen = u32(pyc[funcstart - 4:][:4])
code = pyc[funcstart:][:codelen]
nops = 0
idx = 0
while idx < len(code):
+ if idx in line_starts:
+ print(f' {line_starts[idx]}')
op = u8(code[idx:][:1])
arg = u8(code[idx+1:][:1])
- if op == 32 and arg == 0:
+ if op == 32:
+ assert arg == 0
nops += 1
idx += 2
continue
elif nops > 0:
- print(f' ...{nops} nops...')
+ # print(f' ...{nops} nops...')
nops = 0
if op in known_ops:
opname, hasargs = known_ops[op]
if opname == 'CALL':
- print(f' {op}\t{opname} with {arg} arguments')
+ print(f' {op:>02x} {arg:>02x}\t{opname} with {arg} arguments')
elif opname == 'PRECALL':
- print(f' {op}\t{opname} with {arg} arguments')
+ print(f' {op:>02x} {arg:>02x}\t{opname} with {arg} arguments')
elif opname == 'LOAD_GLOBAL':
- if arg in global_vals:
- print(f' {op}\t{opname} {arg} ({global_vals[arg]})')
+ assert arg % 2 == 0
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({f.co_names[arg//2]!r})')
+ elif opname == 'LOAD_CONST':
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({f.co_consts[arg]!r})')
+ elif opname == 'LOAD_ATTR':
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({f.co_names[arg]!r})')
+ elif opname == 'STORE_NAME':
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({f.co_names[arg]!r})')
+ elif opname in ['LOAD_FAST', 'STORE_FAST']:
+ vartyp = 'arg' if arg < f.co_argcount else 'var'
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({vartyp} {f.co_varnames[arg]!r})')
+ elif opname == 'BINARY_OP':
+ if arg in binary_ops:
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} ({binary_ops[arg]})')
else:
- print(f' {op}\t{opname} {arg} (?????)')
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg} (?????)')
elif hasargs:
- print(f' {op}\t{opname} {arg}')
+ print(f' {op:>02x} {arg:>02x}\t{opname} {arg}')
else:
if arg == 0:
- print(f' {op}\t{opname}')
+ print(f' {op:>02x} {arg:>02x}\t{opname}')
else:
- print(f' WEIRD: {opname} unexpected arg {arg} ({funcname} : {hex(funcstart+idx)})')
+ print(f' WEIRD: {opname} unexpected arg {arg:>02x} ({funcname} : {hex(funcstart+idx)})')
else:
- print(f' {op}\t<{op}>')
+ print(f' {op:>02x} {arg:>02x}\t<{op}> <{arg}>')
idx += 2
print()
First Perfect Decompilation
With this disassembler, we soon had our perfect bytecode matching function. While tiny, it represented a significant milestone. We were almost done.
def w(m,i,j):
return (m >> (i*10 + j)) & 1
Since we were now able to get perfect decompilation in some places, I considered the disassembler to be in a good enough state that I would start decompiling functions by hand, in-parallel to zaratec. We focused on different functions each, so as to not unnecessarily waste time.
Manual Decompilation
Progress now was very fast, with messages on Discord flowing left and right.
f0xtr0t:
69: yield. Nice
130: ('BUILD_TUPLE', True), 117: ('??CONTAINS_OP', True),
zaratec:
116: ('BUILD_LIST', True),
f0xtr0t:
31: ('GET_ITER', False), 182: ('FOR_ITER', True), 27: ('NOP', False),
zaratec:
123: ('JUMP_BACKWARD', ...)
...and so on...
I had not completely stopped improving the disassembler though; each bit that we correctly decompiled gave ideas on how to improve quality-of-life features. I will skip giving a blow-by-blow list of these changes, and instead give the final disassembler at the end.
Tangent: Discovering Python Style Guide Non-Compliance
As an interesting tangent, we discovered that the author of the challenge did not strictly adhere to the style guidelines that Python prescribes, known as PEP-8. In particular, we discovered that the challenge author used 2-space indents, rather than 4-space indents as required for PEP-8 compliance.
Usually, it is hard to detect source-level style information from the
byte-compiled .pyc, since the compilation process (intentionally)
throws away details like indentation. Specifically, the byte code has
no notion of how indented code is (indeed, even conditions and loops
are desugared to goto-like jumps at the point, so the code is no
longer structured).
However, strings must be maintained verbatim, and multi-line strings
in Python are not auto-unindented (instead, they have the full
whitespace prefix maintained on each line). game3 in particular
contains what appears to be such a multi-line string (it could be a
long string with the extremely unusual "\n foo\n bar\n ", but it is
much more likely to be a multi-line string, especially given what we
could discover about line numbers from the disassembly, and where the
code right after it is). When decompiled, prefix of the game3
function looks exactly like this:
def game3(s):
print("Speed typing game.")
t = time.time()
text = '''
Text: Because of its performance advantage, today many language implementations
execute a program in two phases, first compiling the source code into bytecode,
and then passing the bytecode to the virtual machine.
'''
...
Since the string in text is indented exactly by two spaces, we can
infer that the code itself must've been indented by two spaces. After
the contest, if we look at the
source
published by the challenge author, indeed it is two-space indented :D
Anyways, while interesting, this was a interesting tangent. Back to the main story.
More Opcode Reversing
By this point, we had a lot of opcodes figured out, and were just getting final few details right. To make this easier, I added a ranked list of unknown opcode values to the disassembler to make it easier to figure out more faster. I also added a view to make it easier to see where jumps were pointing to as direct line numbers, rather than bytecode offsets.
Finally, we had decompiled x.pyc, and could run the game. Of course,
we patched out the typing speed check, because we can't type that
fast, but otherwise, we could run it as is, and it dumped the flag.
Flage! and Closing Thoughts

Finally, now that we had solved the game, we had a flag:
CTF{4t_l3ast_1t_w4s_n0t_4n_x86_opc0d3_p3rmut4tion}
Indeed, indeed!
Although now I wonder, how fun would it be to solve an x86 opcode permutation challenge? It'd definitely be a harder challenge, but also, with known compiler settings, it'd likely be in the realm of feasibility.
All in all, this was a really fun challenge, and I'm glad I solved it with zaratec, whose expertise neatly complemented my own, and worked out really well to solve this challenge.
This challenge was a nice mix of what makes reverse engineering so interesting and fascinating. It exemplifies the highly scientific yet creative nature of RE, which involves making hypotheses via creative leaps and guesses, and then validating those hypotheses (usually with tooling to help) to make further progress at a better understanding of the system at hand.
Looking forward to what next year's Google CTF brings!
Oh, and if you're looking for the final disassembler, or our final decompiled code just click on the respective links.
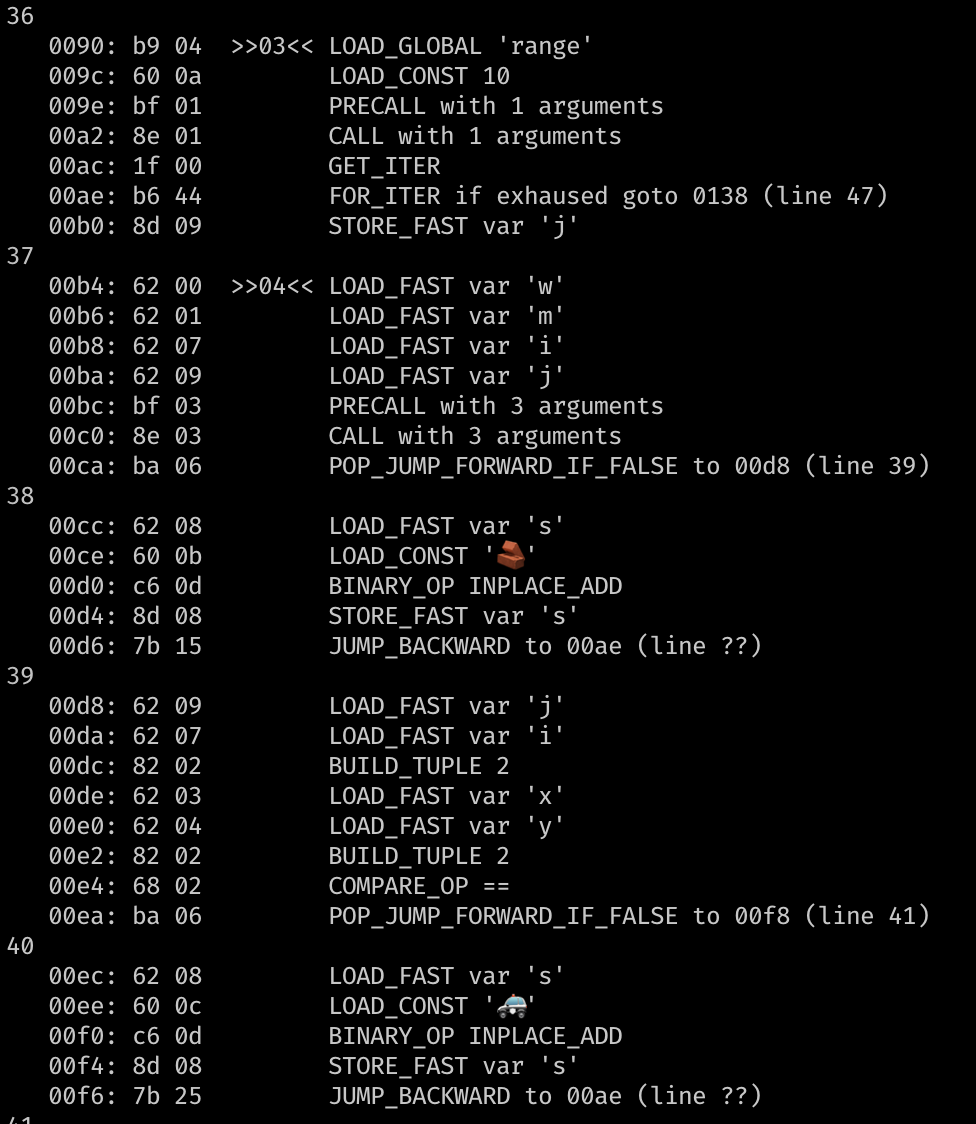
Finally, I leave you with some output produced by the disassembler. Cheers!